基础介绍
go语言圣经开源翻译版
go是一门编译型语言
go通过package组织,一个包由单个目录下一个或者多个go源代码文件组成,每个源文件都以一条package声明语句开始,如package main,表示文件属于哪个包,紧跟着一系列import的包
main包比较特殊,它定义了一个独立可执行的程序而不是一个库,main函数则是程序执行的入口(也许是继承了早期开发时c语言的风格
go不需要用分号换行
package main
import "fmt"
func main() { /*go的左大括号不能单独放在一行,必须以这种一半换行一半不换行的风格写括号,太野蛮了!太野蛮了!*/
fmt.Println("Hello,golang")
}
作为一门编译型语言,当然少不了编译运行。golang提供了go这个工具配合不同指令对你所编写的工程文件进行操作
build:这个指令会把你的工程文件编译成一个二进制可执行文件(在win里面它是exe)
go build example.go
./example
Hello,golang
run:当然,你也可以直接运行
go run example.go
Hello,golang
占位符
example
type Human struct {
Name string
}
var people = Human{Name:"zhangsan"}
//////////////////////////////
%v 相应值的默认格式。 Printf("%v", people) {zhangsan},
%+v 打印结构体时,会添加字段名 Printf("%+v", people) {Name:zhangsan}
%#v 相应值的Go语法表示 Printf("#v", people) main.Human{Name:"zhangsan"}
%T 相应值的类型的Go语法表示 Printf("%T", people) main.Human
%% 字面上的百分号,并非值的占位符 Printf("%%") %
%t true 或 false。 Printf("%t", true) true
%s 输出字符串表示(string类型或[]byte) Printf("%s", []byte("Go语言")) Go语言
%q 双引号围绕的字符串,由Go语法安全地转义 Printf("%q", "Go语言") "Go语言"
%x 十六进制,小写字母,每字节两个字符 Printf("%x", "golang") 676f6c616e67
%X 十六进制,大写字母,每字节两个字符 Printf("%X", "golang") 676F6C616E67
%b 无小数部分的,指数为二的幂的科学计数法,
与 strconv.FormatFloat 的 'b' 转换格式一致。例如 -123456p-78
%e 科学计数法,例如 -1234.456e+78 Printf("%e", 10.2) 1.020000e+01
%E 科学计数法,例如 -1234.456E+78 Printf("%e", 10.2) 1.020000E+01
%f 有小数点而无指数,例如 123.456 Printf("%f", 10.2) 10.200000
%g 根据情况选择 %e 或 %f 以产生更紧凑的(无末尾的0)输出 Printf("%g", 10.20) 10.2
%G 根据情况选择 %E 或 %f 以产生更紧凑的(无末尾的0)输出 Printf("%G", 10.20+2i) (10.2+2i)
%b 二进制表示 Printf("%b", 5) 101
%c 相应Unicode码点所表示的字符 Printf("%c", 0x4E2D) 中
%d 十进制表示 Printf("%d", 0x12) 18
%o 八进制表示 Printf("%d", 10) 12
%q 单引号围绕的字符字面值,由Go语法安全地转义 Printf("%q", 0x4E2D) '中'
%x 十六进制表示,字母形式为小写 a-f Printf("%x", 13) d
%X 十六进制表示,字母形式为大写 A-F Printf("%x", 13) D
%U Unicode格式:U+1234,等同于 "U+%04X" Printf("%U", 0x4E2D) U+4E2D
基础语法
前排提醒,go里面的单引号是字符(byte,rune),字符串只能用双引号
变量、格式化输出、常量
go的变量以var开始,可以是
var age int /*没说明值默认为0,bool为false,字符串为空串,指针等为nil*/
var b bool = true
var identifier1, identifier2 type
var (
vname1 v_type1
vname2 v_type2
)
也可以是
var age = 19
或者也可以不用var声明,采用赋值符:=,但是这只能用在函数内部,不能用于全局变量的申明
number1, number2, number3 := 1, 2, 3
a :=[7]int{1,2,3,4,5,6,7} //go的数组长得真奇怪
q := [...]int{1, 2, 3}
所有被申明的局部变量必须被使用,如果存在未使用的变量会报错
go可以使用fmt.sprintf来格式化语句,然后再用printf来输出,或者直接printf
package main
import "fmt"
func main() {
var name = "zhangsan"
var age = 19
var words = "i'm %s,%d years old"
var format_output = fmt.Sprintf(words, name, age)
fmt.Println(format_output)
}
package main
import "fmt"
func main() {
var name = "zhangsan"
var age = 19
fmt.Printf("i'm %s,%d years old", name, age)
}
td@tddeMacBook-Air blog % go run example.go
i'm zhangsan,19 years old
Println :可以打印出字符串,和变量
Printf : 只可以打印出格式化的字符串,可以输出字符串类型的变量,不可以输出整型变量和整型
Sprintf:按照传入的格式化规则符将传入的变量格式化,(终端中不会有显示,即不会有信息输出在控制台),返回为 格式化后的字符串
讲完变量自然也有常量
常量的命名格式为const identifier [type] = value,类型可以不加,让编译器自己去判断
const LENGTH int = 10
const (
Unknown = 0
Female = 1
Male = 2
)
iota是一个特殊的常量,他第一次出现时被置为0,后面每出现一次+1
const (
a = iota
b = iota
c = iota
)
//a=0, b=1, c=2
const (
a = iota
b
c
)
复合数据类型
数组
跟其他语言的很像,但是要写死长度,内置len
var a [3]int // array of 3 integers
fmt.Println(a[0]) // print the first element
fmt.Println(a[len(a)-1]) // print the last element, a[2]
// Print the indices and elements.
for i, v := range a {
fmt.Printf("%d %d\n", i, v)
}
// Print the elements only.
for _, v := range a {
fmt.Printf("%d\n", v)
}
q := [...]int{1, 2, 3} //表示长度由具体的值来决定
数组也可以用索引的方式来表达
type Currency int
const (
USD Currency = iota // 美元
EUR // 欧元
GBP // 英镑
RMB // 人民币
)
symbol := [...]string{USD: "$", EUR: "€", GBP: "£", RMB: "¥"}
fmt.Println(RMB, symbol[RMB]) // "3 ¥"
r := [...]int{99: -1} //这是个含有100个元素的数组,除了第一百个元素被赋值为-1,其他都为默认值0
切片
尽管数组可以用指针来表示,但是他依旧是值类型的,而且写死的长度会使的他缺少灵活性,所以数组一般不会被用作于函数的参数,而是使用指针类型的切片来替代
切片的底层其实也是一个数组对象,但他没有固定长度。一个slice由指针、长度和容量组成,指针指向第一个切片元素对应的底层数组的元素地址,但是切片的第一个元素并不一定是数组的第一个元素,长度对应来元素的数目,长度不能超过容量,len和cap分别能返回切片的长度和容量。使用append可以添加元素,当添加使的长度超过容量时,那么会分配另外一块更长的内存空间给他,并把原来的数据复制过去
多个切片之间可以共享底层的数据
slice的切片操作可以用s[start:stop]来实现,s[:]表示全部,和数组一样。因为slice包含指针,所以他允许函数修改内部的值
slice只能和nil比较,不能互相比较,而数组可以
打印时可以使用nonempty()来忽略默认值
var b1 []int //和数组长得很像,但是不定长
b2 := make([]int, 3, 5) //使用make来定义,参数为类型、长度、容量,类型和长度不可缺省
import "fmt"
func main() {
var a []string
b := []int{1, 2, 3, 4, 5}
fmt.Print("a", cap(a), len(a))
fmt.Print("b", cap(b), len(b))
a = append(a, "123", "321", "sss")
b = append(b, 6, 7)
fmt.Print(a)
fmt.Print("a", cap(a), len(a))
fmt.Print("b", cap(b), len(b))
}
//a0 0b5 5[123 321 sss]a3 3b10 7%
Map哈希表
map是一个哈希表,他是一个无序的键值对集合,通过key来访问对应的values,不过map中的元素不是一个变量,因此不能对map的元素进行取址操作.其零值也是nil,map间不能互相比较,只能和nil比较,如果想要比较两个map,得用循环实现。map的key必须是可比较类型
//type1
ages := make(map[string]int)
//type2
ages := map[string]int{
"alice": 31,
"charlie": 34,
}
//type3
ages := make(map[string]int)
ages["alice"] = 31
ages["charlie"] = 34
delete(ages, "alice")//删除元素
因为map是无序的,所以每一次遍历的顺序也不同,如果想要按照一定的顺序去遍历,那么必须使用sort先对key排序
import "sort"
var names []string
for name := range ages {
names = append(names, name)
}
sort.Strings(names)
for _, name := range names {
fmt.Printf("%s\t%d\n", name, ages[name])
}
结构体
梦回c系列
go中所有函数参数都是值拷入,如果想让函数能够修改结构体的值,那么必须用指针传入
结构体可以比较
//type1
type Employee struct {
ID int
Name string
Address string
DoB time.Time
Position string
Salary int
ManagerID int
}
//首字母大写的成员是导出的,在JSON中,只有导出的结构体对象会被编码
var dilbert Employee
dilbert.Salary -= 5000
position := &dilbert.Position
*position = "Senior " + *position
var employeeOfTheMonth *Employee = &dilbert
employeeOfTheMonth.Position += " (proactive team player)"
//type2
type Point struct{ X, Y int }
p := Point{1, 2}
//type3
type Point struct{ X, Y int }
p := Point{X: 1, Y: 2}
fmt.Print(p)
go没有类,不过结构体可以使用匿名成员来使用别的结构体。匿名成员的数据类型必须是命名的类型或指向一个命名的类型的指针
type Point struct {
X, Y int
}
type Circle struct {
Point
Radius int
}
type Wheel struct {
Circle
Spokes int
}
var w Wheel
w.X = 8 // equivalent to w.Circle.Point.X = 8
w.Y = 8 // equivalent to w.Circle.Point.Y = 8
w.Radius = 5 // equivalent to w.Circle.Radius = 5
w.Spokes = 20
//在包外部,由于circle和point没有导出,所以不能用简短的方式来访问这些匿名成员的属性
//我们可以以以上的方式直接去访问匿名成员的属性,不过如果我们想要实例化一个,就只能按照下面的语法来
w := Wheel{Circle{Point{8, 8}, 5}, 20}
w := Wheel{
Circle: Circle{
Point: Point{X: 8, Y: 8},
Radius: 5,
},
Spokes: 20, // NOTE: trailing comma necessary here (and at Radius)
}
fmt.Print(w, "\n")
fmt.Printf("%v\n", w)
fmt.Printf("%#v\n", w) //#修饰符会使得输出所有成员的名字
// Output:
// Wheel{Circle:Circle{Point:Point{X:8, Y:8}, Radius:5}, Spokes:20}
w.X = 42
fmt.Printf("%#v\n", w)
// {{{8 8} 5} 20}
// {{{8 8} 5} 20}
// main.Wheel{Circle:main.Circle{Point:main.Point{X:8, Y:8}, Radius:5}, Spokes:20}
// main.Wheel{Circle:main.Circle{Point:main.Point{X:42, Y:8}, Radius:5}, Spokes:20}
判断
if
if 布尔表达式 {
/* 在布尔表达式为 true 时执行 */
} else {
/* 在布尔表达式为 false 时执行 */
}
switch
switch var1 {
case val1:
...
case val2:
...
default:
...
}
select 随机执行一个可运行的 case。如果没有 case 可运行,它将阻塞,直到有 case 可运行。一个默认的子句应该总是可运行的,如果没有case可运行,也没有default,select将会阻塞,直到某个case可以运行
select {
case communication clause :
statement(s);
case communication clause :
statement(s);
/* 你可以定义任意数量的 case */
default : /* 可选 */
statement(s);
}
循环
go没有while,只有for,但是可以达到while的效果
10内加减循环
package main
import "fmt"
func main() {
sum := 0
for i := 0; i <= 10; i++ {
sum += i
}
fmt.Println(sum)
}
// 类似while风格
package main
import "fmt"
func main() {
sum := 1
for ; sum <= 10; {
sum += sum
}
fmt.Println(sum)
// 这样写也可以,更像 While 语句形式
for sum <= 10{
sum += sum
}
fmt.Println(sum)
}
无限循环
package main
import "fmt"
func main() {
sum := 0
for {
sum++ // 无限循环下去
}
fmt.Println(sum) // 无法输出
}
使用range关键字来对可迭代对象(如数组和map)进行循环输出(index和内容
func main() {
a := [3]int{1, 2, 3}
for t, b := range a {
fmt.Println(t, b)
}
}
//省略index或者value
package main
import "fmt"
func main() {
map1 := make(map[int]float32)
map1[1] = 1.0
map1[2] = 2.0
map1[3] = 3.0
map1[4] = 4.0
// 读取 key 和 value
for key, value := range map1 {
fmt.Printf("key is: %d - value is: %f\n", key, value)
}
// 读取 key
for key := range map1 {
fmt.Printf("key is: %d\n", key)
}
// 读取 value,使用废弃占位符
for _, value := range map1 {
fmt.Printf("value is: %f\n", value)
}
}
//map是一种无序键值对结构,map[KeyType]ValueType,默认初始值为nil,需要使用make()来初始化
//直接赋值
import "fmt"
func main() {
a := map[string]string{"key":"嗨","value":"山石"}
for t,b := range a{
fmt.Println(t,b)
}
}
//make初始化
package main
import "fmt"
func main() {
var a map[string]int
a = make(map[string]int)
a["张三"] = 1
for t, b := range a {
fmt.Println(t, b)
}
}
go也拥有break
函数
拥有函数名的函数只能在包级语块中被定义
func function_name( [parameter list] ) [return_types] {
函数体
}
一般来说函数有两个返回值,一个是期望的返回值,一个是错误信息,error类型本身是一个接口类型
example
package main
import (
"fmt"
)
// 定义一个 DivideError 结构
type DivideError struct {
dividee int
divider int
}
// 实现 `error` 接口
func (de *DivideError) Error() string {
strFormat := `
Cannot proceed, the divider is zero.
dividee: %d
divider: 0
`
return fmt.Sprintf(strFormat, de.dividee)
}
// 定义 `int` 类型除法运算的函数
func Divide(varDividee int, varDivider int) (result int, errorMsg string) {
if varDivider == 0 {
dData := DivideError{
dividee: varDividee,
divider: varDivider,
}
errorMsg = dData.Error()
return
} else {
return varDividee / varDivider, ""
}
}
func main() {
// 正常情况
if result, errorMsg := Divide(100, 10); errorMsg == "" {
fmt.Println("100/10 = ", result)
}
// 当除数为零的时候会返回错误信息
if _, errorMsg := Divide(100, 0); errorMsg != "" {
fmt.Println("errorMsg is: ", errorMsg)
}
}
// go run example.go
// 100/10 = 10
// errorMsg is:
// Cannot proceed, the divider is zero.
// dividee: 100
// divider: 0
可变参数:...代表会接受任意数量这个类型的参数
func sum(vals ...int) int {
total := 0
for _, val := range vals {
total += val
}
return total
}
匿名函数:没有名字的函数,可以在函数体里面定义调用
func(参数列表)(返回参数列表){
函数体
}
f := func(data int) {
fmt.Println("hello", data)
}
f(100) //调用
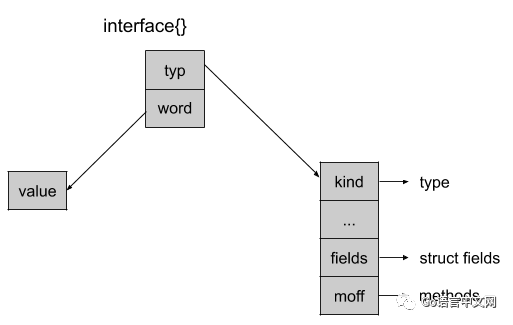
接口
go没有类,但是采用了一种奇怪的方式将结构体和函数联系了起来
接口又称为动态数据类型,在进行接口使用的的时候,会将接口对位置的动态类型改为所指向的类型
会将动态值改成所指向类型的结构体
语法
type interface_name interface { //定义一个接口
method_name1 [return_type]
method_name2 [return_type]
method_name3 [return_type]
...
method_namen [return_type]
}
/* 定义结构体 */
type struct_name struct {
/* variables */
}
/* 实现接口方法,方法和函数的区别在于方法在方法名前面限定了实现的数据结构,可以通过实例名访问该实例的字段name和其他方法 */
func (struct_name_variable struct_name) method_name1() [return_type] {
/* 方法实现 */
}//只传值,不能改变内部的数据
...
func (struct_name_variable *struct_name) method_namen() [return_type] {
/* 方法实现*/
}//指针接收,可以改变值
例子
package main
import (
"fmt"
)
type Phone interface {
call()
}
type NokiaPhone struct {
}
func (nokiaPhone NokiaPhone) call() {
fmt.Println("I am Nokia, I can call you!")
}
type IPhone struct {
}
func (iPhone IPhone) call() {
fmt.Println("I am iPhone, I can call you!")
}
func main() {
var phone Phone
phone = new(NokiaPhone)
phone.call()
phone = new(IPhone)
phone.call()
}
线程、通道
go可以使用关键字go来开启轻量级线程goroutine,goroutine的调度由go运行时决定
语法
go example(x,y,z)
通道能够用来在两个线程之间传递数据
ch := make(chan int)//申明
ch <- v // 把 v 发送到通道 ch
v := <-ch // 从 ch 接收数据
// 并把值赋给 v
ch := make(chan int, 100)//设置缓冲区,如果没有缓冲区,发送方会阻塞直到接收方从通道接收到了值,如果带缓冲,则会阻塞到发送的值被拷贝到缓冲区内。接收方在有值可以接收之前一直会阻塞
example
package main
import (
"fmt"
)
var count int = 0
func sum(s []int, c chan int) {
sum := 0
for _, v := range s {
sum += v
fmt.Print("v,sum", v, sum, "\n")
fmt.Printf("this is %d \n", count)
count += 1
}
c <- sum // 把 sum 发送到通道
fmt.Print(sum, "\n")
}
func main() {
s := []int{7, 2, 8, -9, 4, 0}
c := make(chan int)
go sum(s[:len(s)/2], c)
go sum(s[len(s)/2:], c)
// x := <-c
// fmt.Print(x)
x, y := <-c, <-c // 从通道 c 中接收
fmt.Println("x,y,x+y:", x, y, x+y)
}