用了几个月普罗米修斯了,回头再来补一篇博客(笑
参考:https://blog.csdn.net/cp3_zyh/article/details/124019043
简介
谷歌出品,基于Go编写,容器时代版本的答案!
特点:
- 由指标名+键值对的标签标识的时序数据和转为监控而生的时序数据库TSDB
- promQL
- 自动发现
- 成熟的容器化支持
- 独立部署,无需agent,但是想要获得一些针对性的监控需要对应的exporter
- 基于HTTP采集数据
- 秒级采集精度
- 基于数学模型计算,能够实现复杂的监控逻辑(如计算QPS相关的指标等)
- 数据恢复机制
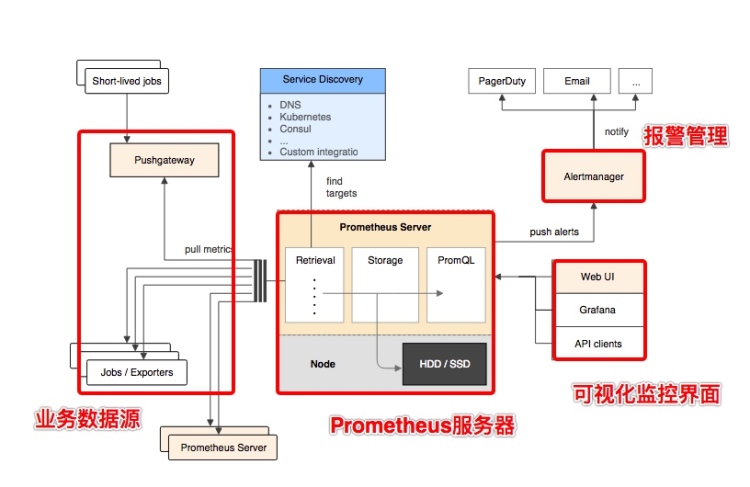
prometheus server可以独立部署,采集目标的数据并存储在tsdb中,自身对外提供promQL,计算告警规则并把触发告警的推送给altermanager
exporter可以帮助普罗米修斯采集数据,目前市面上常见的软件均已有现成的exporter,如mysql\nginx等
pushgateway主要用于针对一些短期存在的job,这些job可以直接向其push metrics,prometheus server周期性过去取数据就行
altermanager从server获取到alter之后,对其进行去重分组后路由至正确的告警方式,支持多种告警格式
serverdiscovery负责动态发现监控对象
普罗米修斯的TS数据库以每两小时为间隔来分block存储,每一个块又分chunk存储,chunk用于存储采集过来的ts数据、index、metadata,index是对metrics和labels进行索引后对存储。后台还会把小block合并成大block以减少内存里block的数量
普罗米修斯使用WAL机制来保护未落盘的数据不会因为突然宕机而丢失,WAL被分割成默认大小为128M的文件段(segment)文件段以数字命名,长度为8位的整形。WAL的写入单位是页(page),每页的大小为32KB,所以每个段大小必须是页的大小的整数倍。如果WAL一次性写入的页数超过一个段的空闲页数,就会创建一个新的文件段来保存这些页,从而确保一次性写入的页不会跨段存储。当出现宕机,等到机器恢复之后,普罗米修斯会把这些数据恢复进内存
Prometheus的数据由指标名称metric、一组键值对、时间戳、指标值组成,键值对可以在配置文件里面自定义,方便后面根据其来用promQL进行数据的分组、筛选等工作。
指标表达方式
<metric name>{<label name>=<label value>, ...}
四种数据类型
Counter
Counter是计数器类型:
- Counter 用于累计值,例如记录请求次数、任务完成数、错误发生次数。
- 一直增加,不会减少。
- 重启进程后,会被重置。
Gague
Gauge是测量器类型:
- Gauge是常规数值,例如温度变化、内存使用变化。
- 可变大,可变小。
- 重启进程后,会被重置
Histogram
histogram是直方图,在Prometheus系统的查询语言中,有三种作用:
1)在一段时间范围内对数据进行采样(通常是请求持续时间或响应大小等),并将其计入可配置的存储桶(bucket)中. 后续可通过指定区间筛选样本,也可以统计样本总数,最后一般将数据展示为直方图。
2)对每个采样点值累计和(sum)
3)对采样点的次数累计和(count)
度量指标名称: [basename]_上面三类的作用度量指标名称_
举例:
对一批访问,分别列出响应时间在0~0.5,0.5~1,1+的数量
[basename]bucket{le="上边界"}, 这个值为小于等于上边界的所有采样点数量
[basename]_sum_
[basename]_count
Summary
Summary即概率图,类似于Histogram,常用于跟踪与时间相关的数据。典型的应用包括请求持续时
间、响应大小等。Summary同样提供样本的count和sum功能;还提供quantiles功能,可以按百分比划
分跟踪结果,例如,quantile取值0.95,表示取样本里的95%数据。Histogram需要计算,summary直接存储
安装与入门示例
https://prometheus.io/download/ 挑版本下载
解压
cp -rf prometheus-2.38.0.linux-amd64 /usr/local/prometheus
./prometheus &运行,默认运行在9090端口
但是注意这种方式启动会使得你丢失普罗米修斯的日志!!你可以配置个systemd或者用nohup来指定输出日志
[root@master prometheus]# ss -tnlp | grep 9090
LISTEN 0 128 [::]:9090 [::]:* users:(("prometheus",pid=373,fd=8))
nohup ./prometheus > /var/log/prom.log 2>&1 & #nohup方式,把输出重定向到了我指定的日志文件里面
普罗米修斯本身还带有一些启动的参数
--config.file=”prometheus.yml” 指定配置文件
-–storage.tsdb.path=”data/” 指标存储的基本路径。
--storage.tsdb.retention=15d 指定保存的数据的时间
当然,因为这里只是演示,我就不加参数了,实际生产环境按需设置
访问端口就可以访问了,阿里云的服务器如果发现访问不了的话,先去安全组里面放行9090端口
关于普罗米修斯的访问控制可以看
https://blog.csdn.net/qq_31725371/article/details/114978760

prometheus的配置文件是prometheus.yml,当然你也可以用--yml来指定配置文件
# my global config
global:
scrape_interval: 15s # 采集间隔Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # 每隔多久执行一次监控规则Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs: #这里开始就是监控项的配置了
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"] #监控对象
这里我们把targets改成targets: ["localhost:9090", "node1:9100"]试试看(node1是另外一台服务器,已经配置了hosts,9100一般是node_exporter的端口
当然,这里得提前在机器上装好node_exporter并启动,安装方式同上,官网下载运行就行,当然,记得放行9100端口

以cpu使用率为例子

查询node_cpu_seconds_total,我们得到了各项cpu使用时间数据,counter类型的

通过cpu占用率的原理可以得知,cpu的使用率=cpu除空闲时间以外的总时间/总时间
所以这里应该这么写
(1-((sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)) / (sum(increase(node_cpu_seconds_total[1m])) by (instance)))) * 100


这个指标是个counter类型,累计的,{}取了带标签为mode="idle"的数据,increase()可以取一段时间内的增长量,因为一台云服务器一般不止1核,会查出多条cpu数据,单核单核看没多少意义,所以用sum进行总和。by instance是按实例拆分数据,如果是集群多机器的时候可以根据主机来区分数据分开展示。[1m]是就取一分钟内的数据,对于cpu这种实时性很强的指标取太长意义不大
((sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)) 分解⬇️
node_cpu_seconds_total{mode="idle"}[1m]
increase(node_cpu_seconds_total{mode="idle"}[1m])
sum(increase(node_cpu_seconds_total{mode="idle"}[1m]))
(sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)
promQL
https://blog.csdn.net/fu_huo_1993/article/details/114482586
这篇比较全,以下是部分
匹配器
使用{}可以通过标签来筛选数据
=: 精确的匹配给定的标签值
!=: 不匹配给定的标签值
=~: 正则表达式匹配给定的标签值
!~: 不匹配正则表格式给定的标签值
=~和!= 必须要指定一个标签名字或者匹配的标签必须要有值
例子:
查询出指标名称up中标签job等于prometheus的时间序列数据
up{job=“prometheus”}
查询出指标名称up中标签job以pro开头的的时间序列数据
up{job=~“pro.*”}
查询出指标名称up中不存在标签env的时间序列数据
时间区间
up[5m] 表示查询5分钟时间内各实例的状态
ms(毫秒)、s(秒)、m(分钟)、h(小时)、d(天)、w(周)、y(年)
d 表示一天总是24小时
w 表示一周总是7天
y 表示一年总是365天
可以将多个不同的时间单位串联起来使用,但是大的时间单位必须在前面,小的时间单位在后面,且不同的时间单位只能出现一次。且不能是小数。
eg: 1h30m可以,但是1.5h则不才可以。
偏移量
表示获取指标名称prometheus_http_requests_total的所有时间序列在距离此刻1分钟之前的5分钟之内的样本。
prometheus_http_requests_total[5m] offset 1m
运算符
+(加)、-(减)、*(乘)、/(除)、%(取模)、^(幂等)
== (等于)、!=(不等于)、>(大于)、<(小于)、>=(大于或等于)、<=(小于或等于)
and(并且-交集)、or(或者-并集)、unless(除非-补集)
如果存在bool修饰符,则结果只返回0,1.如果不使用bool修饰符,那么返回满足结果的个数


匹配
两个即时向量之间进行计算,需要拥有一样的标签才能计算,使用匹配关键字可以帮助我们达成计算目的
向量之间的运算尝试为左侧的每个条目在右侧向量中找到匹配的元素
ignoring:允许在匹配时忽略某些标签。
on:允许在匹配时只匹配指定的标签。
例:
method_code:http_errors:rate5m{method="get", code="500"} 24 和
method:http_requests:rate5m{method="get"} 600
这两个拥有共同的标签method,但是前者多一个code,正常来讲是无法计算的
method_code:http_errors:rate5m{code="500"} / ignoring(code) method:http_requests:rate5m
这种写法让我们忽视前者的code标签,这样两者拥有的标签就一样了
一对多和多对一:“一”的一侧的每个向量元素可以与“多”侧的多个元素进行匹配。必须使用group_left或group_right修饰符显式请求,其中left/right确定哪个向量具有更高的基数
例
method_code:http_errors:rate5m / ignoring(code) group_left method:http_requests:rate5m
内置函数
by 从计算结果从保留该标签、移除其他标签来分组,具体见上面的入门例子
without:与by类似,移除该标签保留其他标签
abs():绝对值
floor():粘贴并匹配样式
increase():返回区间范围内值的增长量,counter
rate():平均增长速率,区间内counter增长量/时间
irate():取最后两个值计算瞬间增长率
sum():合计
topk(n,metric):选出最高的几个值,counter,gague
cout():统计结果的条数
常用组件
https://prometheus.io/download/ 官方组件的下载地址
node_exporter
主机监控
push_gateway
因为pushgateway是被动获取数据,运行起来后取普罗米修斯里面单独给他加一个
- job_name: "pushgateway"
static_configs:
- targets: ["localhost:9091"]
pushgateway可以自己写一些小脚本跑在机器上,定期给普罗米修斯推送
blackbox
端口监测,只能检活
grafana
https://grafana.com/grafana/download/9.1.2
service grafana-server start
以这种方式启动的grafana会使用默认的配置文件和日志文件
/etc/grafana/grafana.ini
/var/log/grafana/grafana.log
访问3000端口

配置数据源,然后建立dashboard或者先建立folder再建立dashboard,建议先建文件夹,grafana有完善的权限控制,后续可以把一个应用的监控面板放在一个文件夹里面,然后把相关的人员放进一个team里面,赋权的时候直接给team赋予权利就行了
容器化方案+自动发现+dashboard
prometheus有docker镜像,可以直接拉取
除此以外还有另外一套通过yaml来部署的项目,或者自己自定义文件来安装(如通过helm等
https://github.com/prometheus-operator/kube-prometheus
这里介绍通过helm编排容器,以及基于文件的自动发现,以下三篇为参考教程
https://yunlzheng.gitbook.io/prometheus-book/part-ii-prometheus-jin-jie/sd/service-discovery-with-file
https://cloud.tencent.com/developer/article/1885193
https://mp.weixin.qq.com/s?__biz=MzU4MjQ0MTU4Ng==&mid=2247495887&idx=1&sn=beddcaebaf6738a2d9f69bf5c35a348c&chksm=fdbaffd2cacd76c41e796065bc11ed608b404587c371281c3f3e3df4b65b81fc26178cbcf310&scene=21#wechat_redirect
docker pull prom/prometheus
docker pull grafana/grafana
在node机器上准备好prometheus.yaml,挂载目录建议提前创建好然后赋权赋高点,不然会出现权限问题导致应用创建失败
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 15s
scrape_configs:
- job_name: file_ds
honor_timestamps: true
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: /metrics
scheme: http
follow_redirects: true
file_sd_configs:
- files:
- /var/file-sd.json
refresh_interval: 1m
helm编写,具体请见http://shangxizhuan.site/archives/411/例子部分
配置完后,尝试访问服务,成功,如果是阿里云之类的记得先放行端口

现在我们来测试一下自动发现功能正不正常,在一台机子上运行期node_exporter,然后去cm里面修改
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-file-sd
namespace: {{ .Values.namespace }}
labels:
app: promtest
data:
file-sd.json: |
[
{
"targets": [ "localhost:9090" ],
"labels": {
"env": "prod",
"job": "local"
}
},
{
"targets": [ "server2:9100"],
"labels": {
"env": "ser2",
"job": "node"
}
}
]
等个一分钟左右就看到新的节点已经被自动加载上来了

这里节点挂了的原因并不是node_exporter,而是这个exporter是单点的,不是集群里的pod,没做路由连接不上
dashboard部分,先拉取官方的recommand.yaml,按需修改
https://github.com/kubernetes/dashboard
http://www.live-in.org/archives/3320.html
如果发现pod起不来,试试安装在master节点,修改下面两处
spec:
nodeName: master节点的名字
containers:
- name: kubernetes-dashboard
image: kubernetesui/dashboard:v2.0.4
imagePullPolicy: Always
spec:
nodeName: master节点的名字
containers:
- name: dashboard-metrics-scraper
image: kubernetesui/metrics-scraper:v1.0.4
443端口相关报错,删除yaml里面检活部分
如果进去发现列不出pod,试试添加角色
https://stackoverflow.com/questions/58719006/kubernetes-dashboard-error-using-service-account-token
https://stackoverflow.com/questions/46664104/how-to-sign-in-kubernetes-dashboard
kubectl delete clusterrolebinding kubernetes-dashboard kubectl create clusterrolebinding kubernetes-dashboard --clusterrole=cluster-admin --serviceaccount=kube-system:kubernetes-dashboard
kubectl create clusterrolebinding deployment-controller --clusterrole=cluster-admin --serviceaccount=kube-system:deployment-controller
获取token
kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | awk '/^deployment-controller-token-/{print $1}') | awk '$1=="token:"{print $2}'
访问url,如果发现打不开,使用https再试试看,出现报错按照上面的方案处理

其他及缺陷
上面给的只是基础的容器化方案,大集群肯定会涉及到高可用的问题,对于这个,比起官方的联邦方案,我更推荐thanos
对存储机制和联邦集群方案的分析在这
普罗米修斯毋庸置疑是容器化环境下监控方案的旗帜,falcon虽好,但是不太支持容器,至于zabbix......什么年代了,还在用传统监控(笑
prometheus本身也是有点点缺陷的,当数据量很大的时候,启动会比较慢,因为其WAL机制,虽然保障了数据恢复机制,但是也使得其在启动的时候必须把还没落盘的数据都加载到内存里面,而且还是一块一块加载(虽然这边给官方提过意见,但是官方表示改不了,就这样)
关于数据采集,除了官方的和社区的那些exporter,一般公司肯定有自己开发的业务,这种一般得自己开发exporter,或者,java应用可以用micrometer打点,毕竟普罗米修斯他跟别的监控不太一样,采集哪些指标、指标怎么进行计算,除了通用的一些,这些只有开发者自己最清楚
https://github.com/micrometer-metrics/micrometer





